GPT4V-大模型输入模式新解
2025-03-16 19:19:43 来源:互联网
在当今科技飞速发展的时代,人工智能领域的创新不断涌现,为我们的生活和工作带来了前所未有的变革。其中,GPT-4V 大模型以其强大的语言理解和生成能力引起了广泛的关注。而对于 GPT-4V 大模型的输入模式,新的解读和理解正为其应用开辟更广阔的前景。
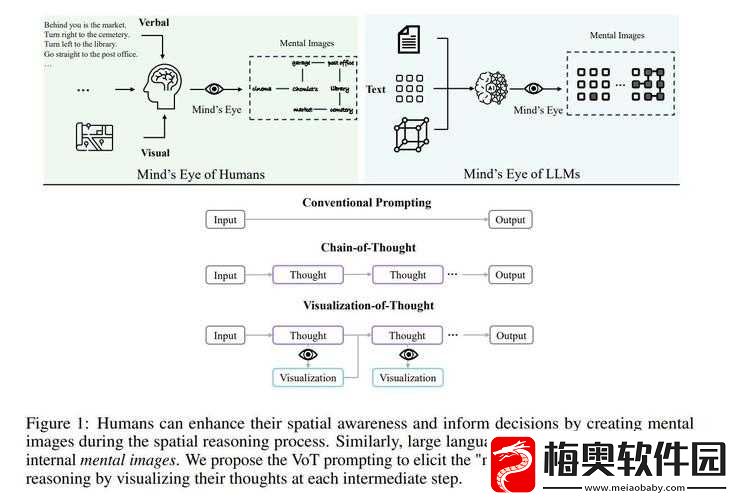
GPT-4V 大模型的输入模式不再仅仅是简单的文字输入,它已经能够处理更加多样化和复杂的信息形式。以往,我们可能只是输入一段描述性的文字,希望得到准确和有用的回答。但现在,新的输入模式允许我们融入图像、音频甚至是多模态的数据,这无疑大大丰富了与模型交互的方式和可能性。
图像输入模式为 GPT-4V 大模型带来了全新的维度。想象一下,我们不再仅仅用文字描述一个场景或物体,而是直接提供一张图片。模型可以对图片中的内容进行分析和理解,提取关键信息,并基于此提供相关的描述、解释或回答问题。这对于需要视觉信息辅助理解的任务,如设计、艺术创作或者对复杂场景的解读,具有极大的价值。例如,在建筑设计中,我们可以向模型提供一张建筑草图,然后询问关于结构合理性、风格适配性或者改进建议等方面的问题。
音频输入模式则为那些更擅长通过语音表达的用户提供了便利。我们可以通过录制一段语音来与 GPT-4V 大模型进行交流,无论是讲述一个故事、提出一个问题,还是分享一段想法。模型能够将音频转换为文字,并进行理解和回应。这对于移动场景中的使用,或者对于那些不太擅长打字的用户来说,是一个巨大的突破。音频输入也为语音识别技术和自然语言处理的结合提供了更深入的应用场景,例如实时的语音翻译、语音助手的智能化提升等。
多模态输入模式是 GPT-4V 大模型输入模式的一个重要发展方向。它将图像、音频、文字等多种信息形式融合在一起,为模型提供更全面、更丰富的输入数据。这种多模态的输入方式能够更真实地反映现实世界中的复杂情况,使模型的理解和生成更加贴近实际需求。比如,在医疗领域,我们可以同时提供患者的病历文字、医学影像图片以及医生的口述记录,让模型综合这些信息进行病情诊断和治疗建议的生成。
随着 GPT-4V 大模型输入模式的新解带来的众多可能性,也面临着一些挑战和问题。首先是数据质量和准确性的问题。无论是图像、音频还是多模态数据,其质量和准确性都会直接影响模型的理解和输出结果。如果输入的数据存在模糊、错误或者不完整,可能会导致模型给出不准确或误导性的回答。在使用新的输入模式时,我们需要确保输入数据的高质量和可靠性。
隐私和安全问题也不容忽视。图像和音频等数据往往包含更多的个人隐私信息,如何在数据传输和处理过程中保障用户的隐私安全,是需要重点关注和解决的问题。开发者和使用者都需要遵循严格的隐私法规和安全标准,采取有效的加密、脱敏等技术手段,防止数据泄露和滥用。
对于新的输入模式,用户的认知和使用习惯也需要一定的时间来培养和适应。虽然这些新的交互方式带来了便利,但对于一些用户来说,可能需要学习和熟悉新的操作方法和技巧。提供清晰易懂的用户指南和培训资源,帮助用户更好地利用这些新的输入模式,是推广和应用的关键。
尽管存在这些挑战,但 GPT-4V 大模型输入模式的新解无疑为人工智能的发展注入了强大的动力。它不仅为各个领域的应用带来了创新的可能性,也促使我们重新思考人类与机器交互的方式和边界。在未来,随着技术的不断进步和完善,我们有理由相信,这些新的输入模式将更加成熟和普及,为我们创造更多的价值和便利。
GPT-4V 大模型输入模式的新解是人工智能领域的一个重要突破。它开启了一扇通向更智能、更灵活、更贴近人类感知的交互之门。我们应当积极拥抱这一变革,充分发挥其潜力,同时也要谨慎应对随之而来的挑战,以实现人工智能技术的可持续发展和有益应用。让我们期待在这一新的征程中,能够创造出更多令人惊叹的成果,为人类社会的进步贡献更多的智慧和力量。